Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs


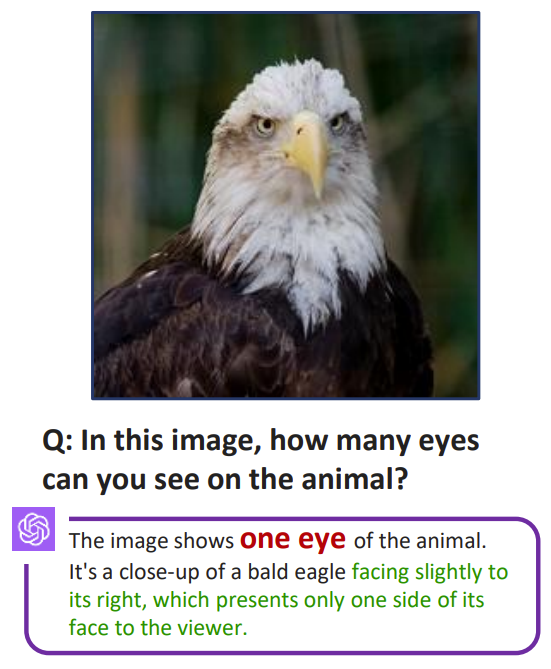




Failure Instances of GPT-4V, Swipe to see more
Is vision good enough for language? Recent advancements in multimodal models primarily stem from the powerful reasoning abilities of large language models (LLMs). However, the visual component typically depends only on the instance-level contrastive language-image pre-training (CLIP) . Our research reveals that the visual capabilities in recent MultiModal LLMs (MLLMs) still exhibit systematic shortcomings.
To understand the visual incapilities of multimodal LLMs, we delve into the visual encoder (CLIP models). We find ambiguities in CLIP embedding via "clip-blind pairs": Images that are visually different yet encoded similarly by CLIP models.

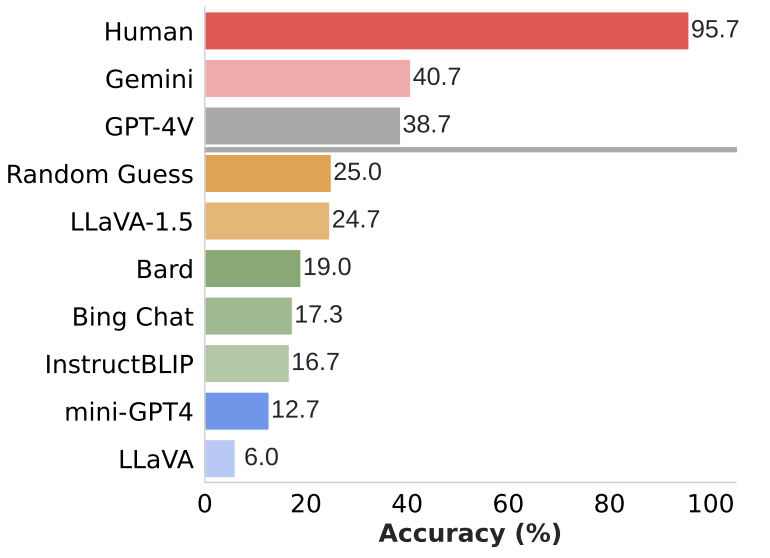
We assess the questions on SOTA open-source models (LLaVA-1.5 , InstructBLIP , Mini-GPT4 ) and closed-source models (GPT-4V , Gemini ,
Bard ). We also evaluate huamn performance through user studies. There is a significant performance gap between human and MLLM models, despite the latter often demonstrating impressive results. Models except GPT-4V and Gemini, scored below random guess level
(25%). Most advanced GPT-4V and Gemini also face challenges in addressing basic visual grounding questions.
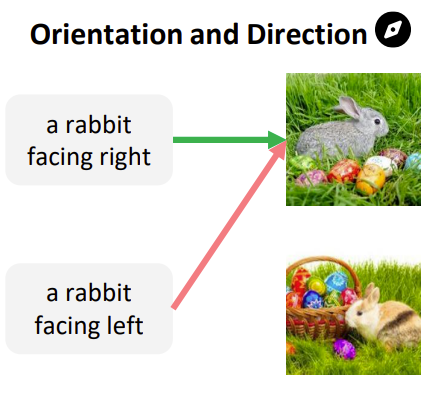
Having identified the CLIP-blind pairs, we summarize systematic visual patterns that the CLIP vision encoders might consistently misinterpret. We turn to the questions and options from the MMVP benchmark. With these questions, we transform abstract visual patterns in images into clearer, language-based descriptors that are easier to categorize. We identify 9 visual patterns:
| Orientation and Direction | |
| Presence of Specific Features | |
| State and Condition | |
| Quantity and Count | |
| Color and Appearance | |
| Positional and Relational Context | |
| Structural and Physical Characteristics | |
| Text | |
| Viewpoint and Perspective |
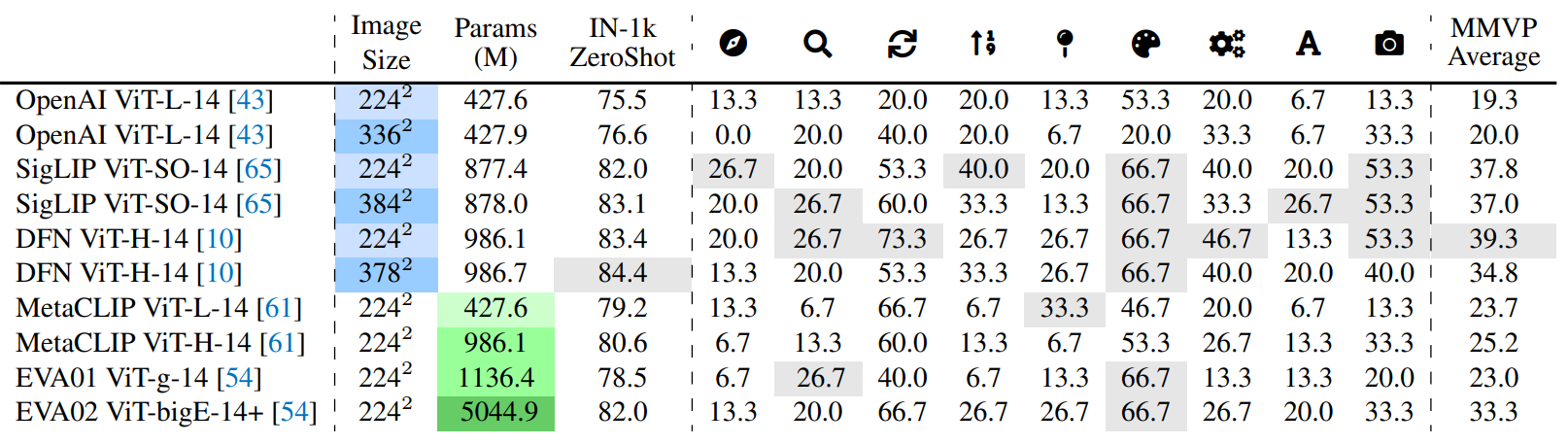
CLIP models develop and scale over the years. We evaluate MMVP on a variety of CLIP models . These models vary in aspects like size, training data, and methodology. As evidenced in the table, increasing network size and training data only aids in identifying two visual patterns – “color and appearance”
and “state and condition”. The rest of the visual patterns continue to challenge all CLIP-based models
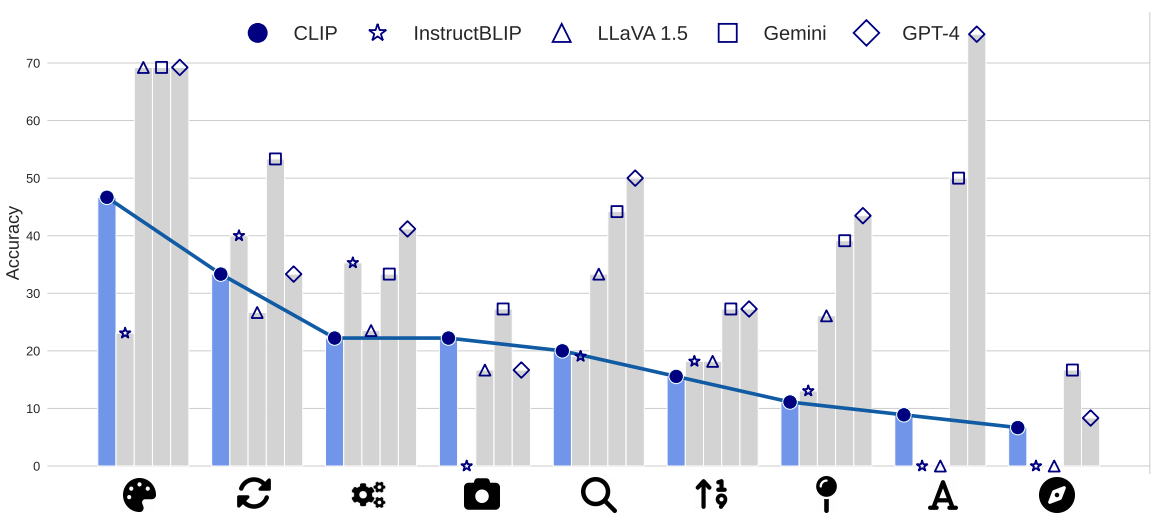
We plot CLIP’s performance and MLLMs' performance for each visual pattern. When the CLIP vision encoder underperforms on a certain visual pattern, the MLLM tends to exhibit similar shortcomings. Open-source models such as LLaVA 1.5 and InstructBLIP that explicitly use the CLIP vision encoder display a strong correlation in performance.
If open-sourced MLLM's visual shortcomings come from the CLIP vision encoder, how do we build a more competent visual encoder? We take initial steps to answer the question by studying Mixture-of-Features (MoF) that mixs Vision-Only SSL (DINOv2 ) features and CLIP features.
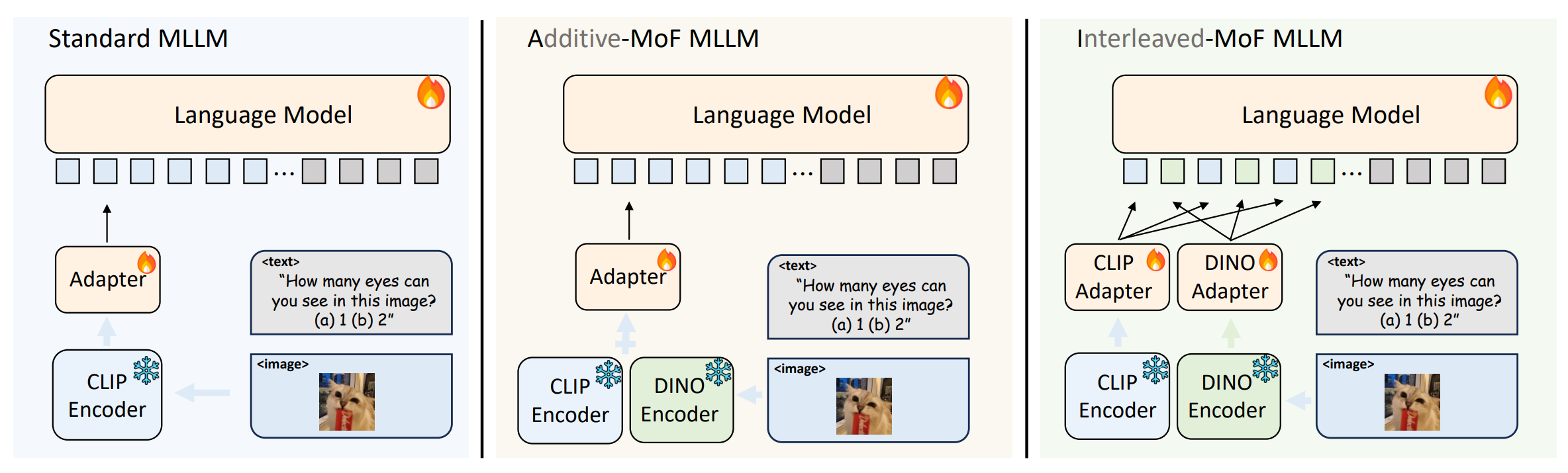
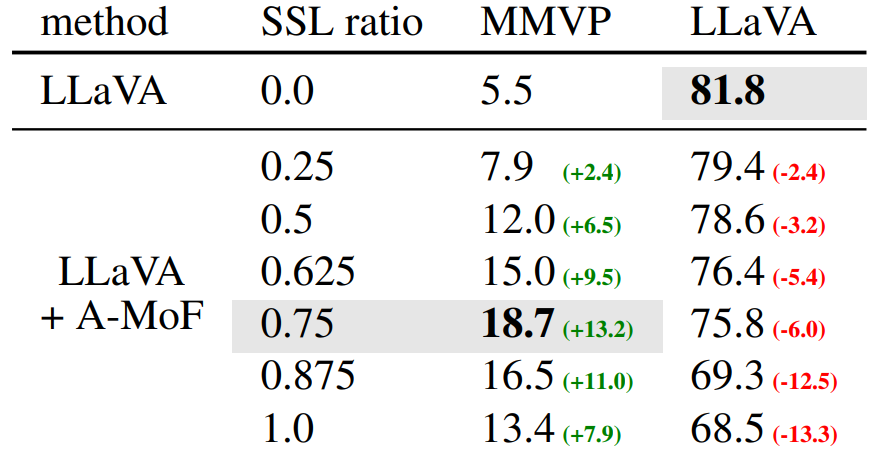
We add a pretrained DINOv2 encoder into MLLM and linearly mix the CLIP pretrained encoder with it. Our study reveals that
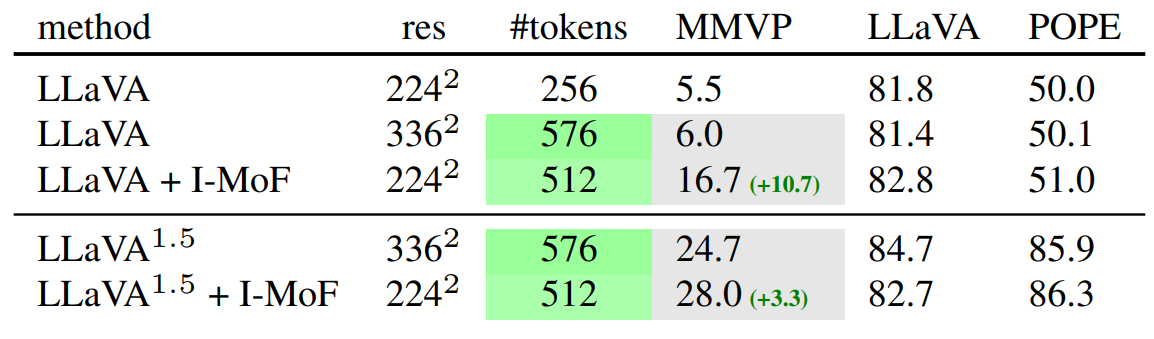
We propose interleaved MoF to leverage advantages from both CLIP and DINOv2 embeddings to enhance image representation. We take the processed features from CLIP and DINOv2 and interleave them while maintaining their original spatial order. Interleave MoF significantly enhances visual grounding, with a 10.7% increase observed in MMVP, without compromising the model’s ability to follow instructions. This experiment is replicated with the LLaVA-1.5 setting and under various image resolution settings, yielding similar enhancements in performance.
@misc{tong2024eyes,
title={Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs},
author={Shengbang Tong and Zhuang Liu and Yuexiang Zhai and Yi Ma and Yann LeCun and Saining Xie}
year={2024},
eprint={2401.06209},
archivePrefix={arXiv},
primaryClass={cs.CV}
}