Peter Tong
Hi, I am Peter Tong, also go by the name Shengbang Tong(童晟邦). I am a second-year PhD student in NYU Courant CS advised by Professor Yann LeCun and Professor Saining Xie. I am funded by OpenAI Superalignment Fellowship (2024-2025) and Meta (2025-2026). I graduated from UC Berkeley with a triple major in Computer Science, Applied Mathematics (Honor) and Statistics (Honor). I am from Nanjing, China and Melbourne, Australia.

Research
I graduated from UC Berkeley with a triple major. I am a second-year CS PhD student in NYU Courant advised by Prof. Yann LeCun and Prof. Saining Xie. I was a researcher in Berkeley Artificial Intelligence Lab(BAIR) advised by Prof. Yi Ma and Prof. Jacob Steinhardt. I am interested in world model, unsupervised/self-supervised learning, generative models and multimodal models. I would like to thank all my mentors-Yubei, Xili, Erik and collaborators for the incredible journey I had in my undergrad.
News
- 2025-06: Our papers Web-SSL and MetaMorph were accepted at ICCV 2025!
- 2025-05: I am re-joining FAIR as a research scientist intern with the amazing Koustuv Sinha!
- 2024-09: Our paper RLVLM was accepted at NeurIPS2024, and Cambrian was accepted at NeurIPS 2024 as an Oral Paper!
- 2024-05: I joined FAIR, Meta for summer internship with Dr. Zhuang Liu, yayyyyy!
- 2024-04: I received OpenAI Superalignment Fellowship! Thank you OpenAI!!! Looking forward to the cool works.
- 2024-04: Our paper Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs was accepted at CVPR 2024 as an Oral Paper!
- 2024-01: Our paper Image Clustering in the Age of Pretrained Models was accepted at ICLR 2024!
- 2023-12: Our papers were accepted at CPAL 2024!
- 2023-09: I am helping organizing the QVCV workshop in ICCV. See you all in Paris!
- 2023-09: Our papers MultiMon and CRATE(whitebox-transformer) were accepted at NeurIPS 2023!
- 2023-07: Our paper Manifold Linearizing and Clustering was accepted at ICCV 2023!
- 2023-05: I graduated from UC Berkeley with triple degree Applied Math (Honor), Statistics (Honor) and Computer Science (No honor, because I didn't want to take 16b and 61c too early, but I published quite some interesting work so yay)!!!
- 2023-04: I will be a CS PhD student in NYU Courant advised by Professor Yann LeCun and Professor Saining Xie. Looking forward to working with Yann and Saining in New York!
- 2023-01: Our paper incremental-CTRL was accepted at ICLR 2023!
Publications
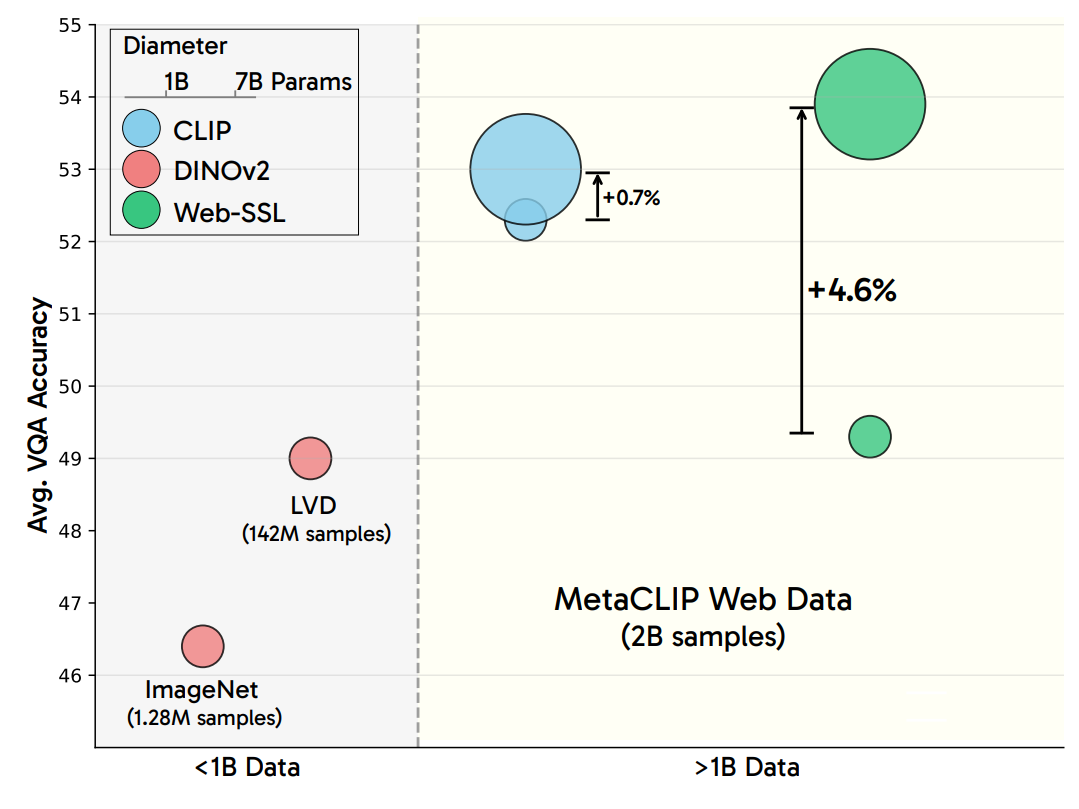
Scaling Language-Free Visual Representation Learning
We introduce Visual SSL 2.0: Scaling up models, data to billion scale and adding VQA to the evaluation suite. Vision-only models scale with model size and data size, eventually catching up/surpassing CLIP models.

MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
Visual understanding and visual generation are mutually beneficial in unified models! But visual understanding data is much more effective than visual generation. Capabilities in LLM can also transfer to unified models such as implicit reasoning!

Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
We provide a vision-centric exploration or cookbook in MLLMs, systematically studying visual representation, vision-language connector, instruction tuning data, training recipe and evaluation protocols. We propose new vision-centric benchmarks, spatial-aware connector, data collection and curation of instruction data, and release very competitive 8B, 13B and 34B models on par with GPT-4V and Gemini.

Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
Is vision good enough for language? Our research reveals that the visual capabilities in recent multimodal LLMs (MLLMs) still exhibit systematic shortcomings. We identify 'CLIP-blind pairs' - images that CLIP perceives as similar despite their clear visual differences. With these pairs, we construct the Multimodal Visual Patterns (MMVP) benchmark.

Mass-Producing Failures of Multimodal Systems with Language Models
Deployed multimodal systems can fail in ways that evaluators did not anticipate. In order to find these failures before deployment, we introduce MULTIMON, a system that automatically identifies systematic failures.
-
From Intention to Execution: Probing the Generalization Boundaries of Vision-Language-Action Models
Technical Report -
Thinking vs. Doing: Agents that Reason by Scaling Test-Time Interaction
Technical Report -
Seeing from Another Perspective: Evaluating Multi-View Understanding in MLLMs
Technical Report -
Scaling Language-Free Visual Representation Learning
ICCV 2025 Highlight -
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
ICML 2025 -
MetaMorph: Multimodal Understanding and Generation via Instruction Tuning
ICCV 2025 -
MMMU-Pro: A More Robust Multi-discipline Multimodal Understanding Benchmark
ACL 2025 -
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
NeurIPS 2024 Oral -
Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning
NeurIPS 2024 -
Connecting Joint-Embedding Predictive Architecture with Contrastive Self-supervised Learning
NeurIPS 2024 Spotlight -
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
CVPR 2024 Oral -
Investigating the Catastrophic Forgetting in Multimodal Large Language Models
CPAL 2024 -
Emergence of Segmentation with Minimalistic White-Box Transformers
CPAL 2024 -
Ctrl123: Consistent Novel View Synthesis via Closed-Loop Transcription
Technical Report -
Mass-Producing Failures of Multimodal Systems with Language Models
NeurIPS 2023 -
Image Clustering in the Age of Pretrained Models
ICLR 2024 -
White-Box Transformers via Sparse Rate Reduction
NeurIPS 2023 -
EMP-SSL: Towards Self-Supervised Learning in One Epoch
Technical Report -
Unsupervised Manifold Linearizing and Clustering
ICCV 2023 -
Closed-Loop Transcription Via Convolutional Sparse Coding
CPAL 2024 -
Unsupervised Learning of Structured Representation via Closed-Loop Transcription
CPAL 2024 -
Revisiting Sparse Convolutional Model for Visual Recognition
NeurIPS 2022 -
Incremental Learning of Structured Memory via Closed-Loop Transcription
ICLR 2023 -
Closed-Loop Data Transcription to an LDR via Minimaxing Rate Reduction
Entropy Journal